GPU Accelerated Machine Learning
OPEN BETA: ACCELERATING SCIKIT-LEARN, UMAP,
AND HDBSCAN WITH ZERO CODE
CHANGE
Zero Code Change Acceleration
Write your code with the ease and familiarity of scikit-learn, UMAP, or HDBSCAN. Just load cuml.accel and run your code on the GPU for maximum performance.
Algorithms for Every Use Case
Accelerating the most popular estimators for classification, regression, dimensionality reduction, and clustering.
Train Models Faster
Up to 50x faster training times for popular machine learning algorithms. Spend less time waiting and more time optimizing your model.
Device Independent Code
Develop on CPU and deploy on GPUs. Or vice versa. All without any changes to your code.
Bringing GPU Acceleration
to Every scikit-learn User
How to Use It
To accelerate IPython or Jupyter Notebooks, use the magic:
%load_ext cuml.accel
import sklearn
...To accelerate a Python script, you can use the Python module flag from the command line:
python -m cuml.accel script.pyOr, explicitly enable cuml.accel in your code via import if you can't use command line flags:
import cuml.accel
cuml.accel.install()
import sklearn
...How It Works
Under the Hood
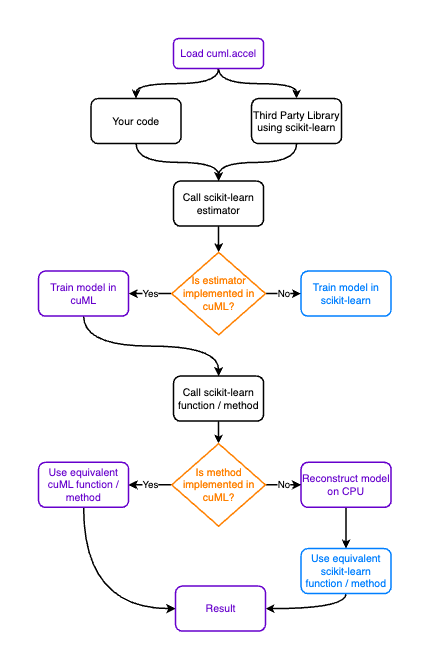
When you load cuml.accel, importing scikit-learn (or umap-learn or hdbscan) allows cuML to "intercept" estimators from these CPU modules. When you create a new estimator to run a machine learning algorithm, a "proxy estimator" is created instead.
In [1]: %load_ext cuml.accel
In [2]: from sklearn.ensemble import RandomForestClassifier
In [3]: from sklearn.datasets import make_classification
In [4]: X, y = make_classification(n_samples=10000, n_features=20)
In [5]: clf = RandomForestClassifier(n_estimators=100)
In [6]: clf.fit(X, y) # Runs on GPU!
Out[6]: RandomForestClassifier()
Estimators that are implemented in cuML will be dispatched to run on the GPU where possible, and fall back to the CPU library otherwise. This applies to scikit-learn operations in your code, as well as third party libraries you may be using.
Execution Flow
Profiling
You can verify that the estimator is a proxy estimator by using the is_proxy function:
In [7]: from cuml.accel import is_proxy
In [8]: is_proxy(clf)
Out[8]: True
This confirms that your RandomForestClassifier is running on GPU through cuml.accel's proxy system.
For more detailed information on what is running on the GPU and what is running on the CPU, you can use the profile function:
In [8]: %%cuml.accel.profile
...: clf.fit(X, y)
...:
...: This will output a table with the function name, the number of GPU calls, the GPU time, the number of CPU calls, and the CPU time. See the documentation for more information.
Get Started with
Accelerated Machine Learning
Try Now on Colab
Get started accelerating your machine learning workflows in a free GPU-enabled notebook environment using your Google account. Launch on Colab
Install cuML
cuML.accel is automatically included with cuML - no separate installation required! Install cuML using conda, pip, or Docker to get started with GPU-accelerated machine learning.
Learn More
cuML-accelerated scikit-learn is in open beta and under active development. It's ready for wide use, but certain estimators come with known issues and limitations. Learn more through the documentation and the release blog
Want to contribute or share feedback, reach out on GitHub